|
■相関分析 【要点】 ・以下は,よく使われるもの・簡単に求められるもののみ. ・統計データの種類(尺度水準)についてはscale1.htm参照 (※ データが標本である場合には,以下で求めているのは標本の相関係数となるので,母相関係数の推定・検定という問題が別に存在することとなるがこのページでは扱っていない.) (1) 右の表1のように,データが「量的変数」(数値)と「量的変数」(数値)の組合わせで与えられるとき,相関係数の計算にはピアソンの積率相関係数 r を利用することができる.(※このページ参照) 相関係数 r は -1≦ r ≦ 1を満たし,r>0のとき正の相関,r<0のとき負の相関,rが0付近のとき相関がないと考える. ア) 相関係数の定義から求めるときは次の定義による. (ただし,mはxkの平均,nはykの平均) |
表1
※ ピアソンの積率相関係数は外れ値(例外的に飛び離れた値)の影響を受けやすく, I) 他のn-1個の標本だけなら相関が見られないときに外れ値を含めただけで「相関らしいものができてしまう場合」や, II) 逆に,他のn-1個だけならば相関が見られるときに外れ値を含めただけで「相関がなくなる場合」がある ので,数値計算だけでなく散布図によって外れ値の存在を確認しておくことが重要だと言われている. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (2) 右の表2のように,データが「量的変数」(数値)と「質的変数」(カテゴリーデータ)の組合わせで与えられるときは,相関比を利用することができる. 平均値の差が有意差と見なせるかどうかは分散分析によって判断できるが,河川と鮎の体長には,次の式で定義される相関比η2(イータ2乗)が利用できる. 相関比η2 = (群間変動)/(全変動) ※ 「一元配置の分散分析」と同じ考え方であるが,分母が全変動となっているので0≦η2≦1となる. |
表2 釣れた鮎の体長(架空データ)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (3) 右の表3のように,デ−タが「順位尺度」の組で与えられているとき,スピアマンの順位相関係数ρを利用することができる. ア) (例) 1位,2位,2位,4位,5位,・・・ ===> 2位の2つは,2位,3位を分けたものだから,各々2.5位とし, 1,2.5,2.5,4,5,・・・ とする. イ) スピアマンの順位相関係数は,順位を単なる数値と見なして「ピアソンの積率相関係数」に当てはめたものに等しいので,Excelの分析ツールで単に相関を出力したものと同じになる. ※ スピアマンの順位相関係数は,「順序尺度」のデータに四則演算を行うため,理論的な弱点が指摘されることがある. |
表3 県庁所在都市における1世帯当り消費量(g)の多い順
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (4) 右の表4ように,データが「質的変数」(カテゴリーデータ)と「質的変数」のクロス集計表(分割表)で与えられるとき, または,右の表5のように「量的変数」の組が階級分けしてクロス集計のみ与えられ,元データが不明のとき(元データがあるときはピアソンの相関係数でやればよい), クラメールの連関係数(クラメールのV,独立係数)を利用することができる. これは,χ2分布を用いた「独立性の検定」を少し変形したものとなっている. ※ クロス集計表(分割表)の作り方はこのページ 右の表O,表Eを用いて3行4列で解説する. χ2値は右の表Oのような観測値に対して,その周辺和から比例配分した期待度数を表Eのように作成し, χ2 = 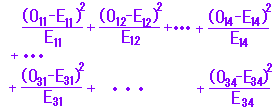 を計算したものであるが,この値は 0≦χ2<∞ の値をとる.(項目1〜4と項目A〜Cが独立のとき,χ2値は0となる.) この値χ2を要素の個数によらず0〜1の値をとるように調整した次の値をクラメールの連関係数(独立係数)という. |
表4
表O
|
