|
次にような場合に「対応のある場合のt検定」…「 一対の標本による平均の検定」「対応のある2群の平均値差の検定」「データに対応がある場合のt検定」とも呼ばれる…を用いる.
○1 同一の被験者に対して異なる2つの条件で測定したとき,それぞれの条件下での母集団平均が等しいかどうかの比較を行う場合
例1
右の表1は定期健診での最高血圧の一覧表であるものとする.No欄は被験者の整理番号,A欄は昨年の定期検査時の最高血圧,B欄は今年の定期検査時の最高血圧とする. この一覧表では12人の被験者について,昨年の定期検査時と今年の定期検査時の最高血圧が対のデータとなっている. これらのデータからA欄の値とB欄の値を比較すると,A欄のデータとB欄のデータは同一被験者のデータであるので,昨年と今年という条件だけが異なることになり,昨年の最高血圧と今年の最高血圧に有意差があるかどうか調べることができる.(単にA欄とB欄のデータの件数が等しく,A欄が昨年のB欄が今年のデータであるというだけで対応のあるt検定が使える訳ではなく,A欄とB欄が同一被験者のデータとして対応があることが重要) この場合において,昨年と今年で有意差があるかどうかを調べるのだから両側検定を用いるとよい.  |
表1
※例1のような検定を行うためには,母集団についてA欄のデータ,B欄のデータ,A-Bの値が各々正規分布していることが前提となる. 取り扱っているデータがそもそも正規分布にならないという有力な学説がある場合(例えば,演歌やロックのような特定ジャンルの音楽に対する大人の好感度,数学や英語などの教科に対する生徒の好き嫌いなどを数値化したとき,値は正規分布にならない・・・好き嫌いが分かれて双峰形になる・・・という有力な学説があれば),安易に正規分布を仮定できないが,特に引っかかる事情がなければ多くの場合,母集団の値の分布,差の分布は正規分布をなすものと見なせばよい. ※このような「対応のある場合のt検定」を適用する場合には,A欄のデータとB欄のデータが等分散であるか否かによって,以後の処理を分ける必要はない. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
例2
右の表2はあるダイエット法を行う前と後の体重の一覧表であるものとする.No欄は被験者の整理番号,A欄は実施前の体重,B欄は実施後の体重とする. この一覧表では8人の被験者について,ダイエット法実施前後の体重が対のデータとなっている. これらのデータからA欄の値とB欄の値を比較すると,A欄のデータとB欄のデータは同一被験者のデータであるので,A欄とB欄の差はダイエット法の効果と見ることができる. この場合,ダイエット法の効果があるとは「体重が減少している」という意味であるから片側検定を用いるとよい.  |
表2
※片側検定の境界値は両側検定の境界値よりも内側に来るので,同じt値でも両側検定では棄却域に入らず片側検定ならば棄却域に入ることがある. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
例3
右の表3は2つの指導法A,Bを行った後のある教科の得点一覧表であるものとする.No欄は被験者の整理番号,Aは指導法A,Bは指導法Bを行った後の得点とする. 同一の被験者に相前後して異なる2つの指導法を行った場合には,後で行う指導のときに前に行った指導による影響が残っている場合がある.例えば,出題範囲が同一であるときの試験では,後で行う試験の得点が高くなると予想されるが,異なる出題範囲であっても前の指導によって「学習習慣が身についてくる」「学習意欲が変化してくる」といった間接的な影響は有り得る. このように,同一被験者に対して異なる2つの条件で試験を行うときに,順序による効果が有り得る場合は,被験者のうちの半数をA→Bの順に,残り半分をB→Aの順に行うなどの工夫をしなければならない.(背景色がピンクのデータは先に行い,空色のデータは後で行うというように実施の順序を変える) 順序の交換は表3の一覧表では数値としては表れておらず,後で解説するコンピュータ処理として行うことはできないので,この一覧表を作る前に行われている必要がある. このように,コンピュータ処理上は,t検定が簡単に行えても,測定が2つの要因A,Bの違いだけを反映しているかどうか,他の要因が入り込んでいないかということは,コンピュータ処理以前の測定の段階で考慮されていなければならない.そうでないと,ガラガラポン統計とかクリック統計などと悪口を言われても仕方がないような分析に陥ってしまう. |
表3
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
○2 被験者が異なっていても双子の兄弟姉妹,夫婦のように対応のある被験者のデータを比較する場合
例4
右の表4は異なる環境で育った一卵性双生児の20歳の時点での体重の一覧表であるとする.Noは一卵性双生児の組の番号,A,Bは各々の体重とする. 一般に人間の特性や能力には遺伝的な要因(先天的なもの)と環境的な要因や本人の努力によって変わる要因(後天的なもの)があるので,遺伝的な要因が同じと見なせる組について,育った環境や教育・学習による差異があるかどうか調べることによって,身長・体重・能力・好みなどについて後天的な要因が大きいかどうかを調べることができる. 後天的な要因が同じで,先天的な要因が異なる対を選ぶことによって先天的な要因の大きさを調べることも考えられる(両親が異なる子供を同一の家庭で育てている場合). 双子とか夫婦の対を選ぶのは,測定条件A,B以外の要因を等質化してA,Bの違いによる差異を調べるためなので,これら以外に意識されていない要因が働く場合には単にt検定が結果が出たというだけでは何も示されていない場合がある. 例えば,右の表が各々同居している夫婦のコレステロール値であるとき,夫婦は同じような食事をするので,食事が同じときにコレステロール値の高低に同じ傾向が見られるかどうか(同じメニューでもコレステロール値に差異があるかどうか)という調査で有り得る.しかし,A欄を夫,B欄を妻に割り当てると,AB間には男女による差異が入ってしまうことになる. ※ このように,被験者が異なる場合でも「対応のある場合のt検定」を使うことがあるが,それらは測定条件A,B以外の要因を等質化することがねらいである. ※ 一般に,自然科学の実験とは異なり社会,心理,教育分野の測定では,非常に多くの要因が働いているので他の要因を完全に等しくすることはできない.そこで,他の要因が可能な限り等質になるようにサンプルの選び方を工夫するとともに,他の要因については相殺されるようにデータを配置する方がよい.(半数について測定の順序を入れ替える,夫と妻の欄を入れ替えるなど) |
表4
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
○3 中学1年生で,数学の担当者が異なる2つの学級から中学入学時の診断テストの得点が等しい対を選んで学年末の数学の得点を比較し,各担当者による教え方の違いによって学年末の得点に有意差があるかどうか比較する場合
※異なる2つの測定を同一環境で行う方が測定しようとしている要因以外の効果を等質化できるが,同時に2つを行えないことがある.(例えば生産者の氏名や似顔絵を貼り付けた商品と従来型の商品とで売上に違いがあるかどうかを調べたいときは,同一店舗の中で両方とも売ればよい.)
しかし,上記の例では中学1年生の数学の授業は一生に1回きりのことなので,2人の人がお互いに影響せずに1人の生徒に教えることはできない.このような場合に,他の要因を等質化するために,入学時の得点が等しい対を選んでいる.(「初等統計学」[培風館/P.G.ホーエル著,浅井晃・村上正康訳]には,さらに他の教科の得点もほぼ似ている生徒の組を選ぶという例が示されている)
例5
右の表5は異なる2人の担当者による1年間の授業の結果として,学年末の数学の得点に差異があるかどうかを調べたもので,No欄は生徒の対の整理番号,A欄は担当者Aに教えてもらった生徒の学年末の得点,B欄は担当者Bに教えてもらった生徒の学年末の得点とする. この表においては,中学入学時の診断テストの得点はどこにも表れていないことに注意.No1の対は40点と40点,No2の対は56点と56点,No3の対は65点と65点,...のように横に並んでいる2人の対ごとに診断テストの得点は等しいが,整理番号が異なる対では得点は一般には異なる(たまたま同じものがあるのはよい.) ※この例では,人的な属性(同一被験者,双生児,夫婦)とは全く無関係に対が選ばれている. |
表5
※このような比較においては,「異なる2人の担当者による授業」という要因以外の要因が可能な限り等しい方がよい.できれば,他の教科の得点もほぼ似ている方がよい・・・もっと言えば,出身小学校,男女別,学習塾に通っているかどうかなども各対について等しい方がよいが,このように条件を絞り過ぎると条件を満たすサンプルがなくなってしまう. そこで,対となるサンプルを選ぶときに考慮できない多くの要因については,無作為抽出による等質化を図る.ただし,この無作為抽出によって等質化できているかどうかは証明されないリスクを含んでいるので,考慮されなかった要因のうち何らかの要因が結果に影響するという有力な学説があれば,この分け方ではまずいことになる.そのような要因があれば,その要因の有無に応じて表3のように半数ずつ入れ替えてその効果を相殺する必要がある. |
|
■Excelを使ったt検定
(1)
表1のデータを使って例1で述べた「対応のある場合のt検定」を行うには
上の表1のデータをExcelに転記するには,画面上でドラッグ→反転表示→右クリック→コピーしてから,Excel上で貼り付ける.(右の図1は解説用で,これをコピーすると行見出し(1~13),列見出し(A~C)の部分[灰色部分]が余計に入り1行1列ずつずれるので,コピーする場合は上の表1の方がよい.)
Excelワークシートの左上端に,表1のデータが右図のようにできたとするとき,例1の両側検定を行うには○1 最も簡単な方法として「分析ツール」を使う方法
Excel2002の場合
ツールのメニューに「分析ツール」がないときは,ツール→アドインで分析ツールにチェックを付けます.
ツール→分析ツール→t検定:一組の標本による平均の検定→[OK]→右図のようなダイアログ画面(対話型入力画面)になるので,変数1の入力範囲(1)にはB1:B13と書き込む(絶対参照の記号$マークは自動で入る),または,その入力欄の右にある  をクリックして,B1からB13までをドラッグする(表題B1も入れるか入れないかによって「ラベル」欄にチェックを入れるかどうかが変わる) をクリックして,B1からB13までをドラッグする(表題B1も入れるか入れないかによって「ラベル」欄にチェックを入れるかどうかが変わる)→変数2の入力範囲(1)にはC1:C13と書き込む(絶対参照の記号$マークは自動で入る),または,その入力欄の右にある をクリックして,C1からC13までをドラッグする(表題C1も入れるか入れないかによって「ラベル」欄にチェックを入れるかどうかが変わるが,取り扱いは変数1にそろえる)
→帰無仮説との差異の欄は空欄のまま放置すれば,自動的に0が入り,「2つの変数の平均の差が0」(2つの変数が等しい)が帰無仮説となる.例えば,この欄に5を記入すると,「2つの変数の平均の差が5」を帰無仮説として「2つの変数の平均の差が5にならない」を対立仮説とすることになる.
→上の例のように変数1,2の入力範囲にA,Bというラベルも含めているときには,「ラベル」欄にチェックを入れる.(そうでないとき,B2:B13とC2:C13を変数の入力範囲にするときはチェックを入れない.ただし,ラベルがなければ作ってでも入力欄にラベルを含める方が結果は分かり易くなる.)→有意水準5%の検定を行うときは,αとして0.05を書きこむ(%でなく小数で書く.)
→何度も検定を繰り返すような場合に,その都度新規ワークシートを増やしていくと,見づらく複雑になるのを防ぐには「出力オプション」を選んで,出力先セル(範囲というよりは左上の1つのセル番地)を指定するとよい.分析ツールでは指定されたセルから右下に14行3列の範囲に出力結果を書き込むので,右側下側が空欄になっているセルを指定する.(空欄になっていないとき「上書きする場合はOKを押してください」という警告が出て,あえて行うとそこにあったデータは上書きされてなくなる.)
→図3のように出力結果が書きこまれる.片側検定のときは青色の背景色で示した部分を,両側検定のときは桃色の背景色で示した部分を読むことになる.
この例のようにA欄の平均がB欄の平均よりも大きい場合はt値が正になり,逆の場合はこれと符号だけが逆の負の値となるがそれ以外は同じものになるが,使うときは|t|の値が背景色が青色または桃色で示した値よりも大きいかどうかで判断する.
→図5のようにまとめる.この例では両側検定なので,桃色で示した欄を読み,t境界値両側(両側検定で有意差が認められる境界値)が2.2...となるのに対して与えられたデータから計算したt値が1.39...だからt値が境界値よりも小さくA,B2群のデータが等しいという帰無仮説の採択域に落ちる.したがって,帰無仮説は棄却されず「有意差は認められない」.
有意差の有無の文章.(両側検定か片側検定か:t(自由度)=t値,p値の範囲) の順
Excel2007の場合
ツールのメニューに「分析ツール」がないときは,一番上左のExcelボタンを押して,(右下にある)Excelのオプション→アドイン→管理欄がExcelのアドインになっている状態で「設定」をクリック→分析ツールにチェックを付けてOK
データ→データ分析から入り,以後の操作は上記に同じ Excel2010の場合
ツールのメニューに「分析ツール」がないときは,一番上左のファイル→オプション→アドイン→(右下にある)Excelのオプション→アドイン→管理欄がExcelのアドインになっている状態で「設定」をクリック→分析ツールにチェックを付けてOK
データ→データ分析から入り,以後の操作は上記に同じ |
図1
 図3
図4 図5 ・・・有意差は認められない.(両側検定:t(11)=1.39, p>.05) ※t( )の中に書き込む数字は,データの組数12ではなく自由度で,データの組数-1=11になる.
分析ツールの出力として書きこまれた表は
1. 「元に戻す」ボタンによって戻すことはできない.(罫線だけは戻る) 2. 分析ツールで出力を書きこんだ後に元のデータを書き換えたとき,新たなデータに追随しない(更新されない).
表1から表5のようにデータそのものが与えられているときは,Excelの分析ツールを使って対応のあるt検定を行うことができるが,
2つの群について平均,標準偏差,相関係数などの要約データが与えられているときは,Excelの分析ツールではt検定はできない. 必要な場合は,次の公式に値を代入して計算することとなる.(この頁参照)  |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
○2 ワークシート関数を使ってt検定を行う方法
図1のようにデータがあるとき,(1) ワークシート関数を直接入力するとき(Excel2002, 2007, 2010とも共通) p値を書きこみたいセルに ・・・[第3引数は両側検定のとき2,片側検定のとき1] ・・・[第4引数は対応のある場合1,等分散が仮定できるとき2,非等分散のとき3] ※第1引数と第2引数の入力範囲にラベル(B1とC1)を含めるかどうか:ラベルが文字データ(A、Bなど)であるときは=TTEST(B1:B7,C1:C7,2,1)のようにラベルを含めて指定しても同じ結果が得られる.ラベルが数値データ(1, 2など)であるときに,入力範囲にラベルも含めてしまうと間違った計算結果が出力される.(このワークシート関数によって返されるのは単なるt値なので,分析ツールの出力結果のようにラベルの有無によって読みやすさは変わらない.そこで,間違いを避けるためには,ラベルを含めずに入力範囲を指定するほうがよい.)
返される値はt検定を行ったときの出現確率:分析ツールで出力される P(T<=t) 両側 0.191236851 と同じ値となる.このp値が p>0.05 となるから有意差はないと判断できる.
ワークシート関数 TTEST()を使ってp値を求めたときは,
結果が得られて後に元のデータを書き換えたとき,新たなデータに追随する(p値は更新される).
表1から表5のようにデータそのものが与えられているときは,Excelのワークシート関数を使って対応のあるt検定を行うことができるが,
2つの群について平均,標準偏差,相関係数などの要約データが与えられているときは,Excelの1つのワークシート関数ではt検定はできない. 必要な場合は,次の公式に値を代入して計算することとなる.(この頁参照) |
(2) 対話型メニューを使って関数を書きこむ場合(Excel2002, 2007, 2010とも共通) 挿入→ワークシートの上端の上にあるfxをクリック→(関数の分類として統計を選択)TTEST→OK (下図6の対話型メニューが表示される)→配列1にB2:B13(または,その入力欄の右にある をクリックして,B2からB13までをドラッグする);配列2にC2:C13(または,その入力欄の右にあるをクリックして,C2からC13までをドラッグする);尾部には上記の第3引数の両側検定を表す2を書きこむ(この数値は選択するときにアシストとして表示される);検定の種類には上記の第4引数の対応のある場合を表す1を書きこむ(この数値は選択するときにアシストとして表示される)→OK図6 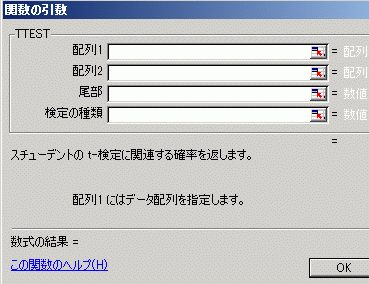 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
【問題1】表2のデータについて,このダイエット法には効果があるかとうか有意水準5%の片側検定で判断してください.
(小数第3位を四捨五入して小数第2位まで答えるものとする)
データを転記するには,画面上でドラッグ→反転表示→右クリック→コピーしてから,Excel上に貼り付けるとよい.
次の空欄を埋めてください. |
分析ツールを用いると次のような出力を得る.
赤色で示した数値を小数第2位まで答えるとよい.
|
||||||||||||||||||||||||||||||||||||||||||
|
【問題2】表3のデータについて,2つの指導法による得点の有意差があるかどうか有意水準5%の両側検定で判断してください.
(小数第3位を四捨五入して小数第2位まで答えるものとする)
データを転記するには,画面上でドラッグ→反転表示→右クリック→コピーしてから,Excel上で貼り付けるとよい.
次の空欄を埋めてください. |
分析ツールを用いると次のような出力を得る.
赤色で示した数値を小数第3位を四捨五入して小数第2位まで答えるとよい.
|
||||||||||||||||||||||||||||||||||||||||||
|
【問題3】表4のデータについて,A,Bの母集団平均に有意差があるかどうか有意水準5%の両側検定で判断してください.
(小数第3位を四捨五入して小数第2位まで答えるものとする)
データを転記するには,画面上でドラッグ→反転表示→右クリック→コピーしてから,Excel上で貼り付けるとよい.
次の空欄を埋めてください. |
分析ツールを用いると次のような出力を得る.
赤色で示した数値を小数第3位を四捨五入して小数第2位まで答えるとよい. (左の欄Aの平均値が右の欄Bの平均値よりも小さいとき,t値は負の値になる.t値の境界値と比較するときは,この絶対値と比較する.p値は正の値で表示される.)
|
||||||||||||||||||||||||||||||||||||||||||
|
【問題4】表5のデータについて,A,Bの母集団平均に有意差があるかどうかTTEST関数を使って有意水準5%の両側検定で判断してください.
(小数第3位を四捨五入して小数第2位まで答えるものとする)
データを転記するには,画面上でドラッグ→反転表示→右クリック→コピーしてから,Excel上で貼り付けるとよい.
次の空欄を埋めてください. |
データをA1からC14の範囲に貼り付けるものとし,A群はB1からB14,B群はC1からC14の範囲に来るものとすると,
TTEST(配列1, 配列2, 尾部, 検定の種類)において
配列1にはB1:B14
配列2にはC1:C14 尾部には2 検定の種類には1 を各々代入すると,p値として0.56...が返される. |
