|
��Excel���g�����Ή��̂Ȃ��ꍇ�̂������…���E��� ���Ή��̂Ȃ��ꍇ�̂����� �@�Q�Q�̕�W�c���ς��r�������Ƃ��ɁC��P�Q�̃f�[�^�Ƒ�Q�Q�̃f�[�^���u����팱�҂ɑ���Q�̏����ł̊ϑ����ʁv�u�e�g���Z��̐g���f�[�^�v�u�e�g�����w�̓��_�̓��������k�̉p��̓��_�v�Ȃǂ̂悤�ɁC�P�Ƀf�[�^�����������ł��邾���łȂ���P�Q�̃f�[�^�Ƒ�Q�Q�̃f�[�^�̊ԂɑΉ�������ꍇ�́C�u�Ή��̂���ꍇ�̂������v��p���邱�Ƃ��ł���D �@����ɑ��āC�Q�Q�̃f�[�^���݂̊Ԃɂ͌ʂ̑Ή����Ȃ��ꍇ�́u�Ή��̂Ȃ��ꍇ�̂������v��p����D
�}�P
 �@�Ή��̂Ȃ��ꍇ�̂�����́C�Q�Q�̕W�{�����������ꍇ�ɂ��������Ȃ��ꍇ�ɂ��g���邪�C�Q�Q�̕��U���������ƌ��Ȃ���ꍇ�Ɠ������Ƃ͌��Ȃ��Ȃ��ꍇ�Ƃł��K�p����������قȂ��̂ŁC�Ή��̂Ȃ��ꍇ�̂�������s�����߂ɂ́C���߂ɕ��U���������ƌ��Ȃ��邩�ǂ����̌���i�e����j���s���D
��P
�@�E�}�Q��20�C�̌{�̂���������10�C�Ɏ����P���C�c���10�C�Ɏ����Q�����ꂼ��P�����ԗ^�����Ƃ��̑̏d�����i���j��\���Ă�����̂Ƃ���D �@�����Q��ނ̎����ɂ��̏d�̑����ɂ͗L�Ӎ������邩�ǂ������肵�Ă��������D
�@�ǎ҂��f�[�^��]�L����Ƃ����C�}�Q�̃f�[�^����ʏ�Ńh���b�O�����]�\�����E�N���b�N���R�s�[��Excel�̃��[�N�V�[�g����[�ɓ\��t������̂Ƃ���D�i�ȉ��̖��ɂ��Ă����l�j (*) �����P�̃f�[�^�Ǝ����Q�̃f�[�^�͂��܂��ܓ����ɂȂ��Ă��邪�C����͈ȉ��̌���̐i�ߕ��ɊW�Ȃ��D���ꂼ��̉��̕��т̃f�[�^�ɂ͉����Ή����Ȃ��Ƃ������Ƃ��d�v�D�i20�C�̌{�̂��������������P�Ɏc�蔼���������Q�Ɋ��蓖�Ă�����������D�j (1) �e������s��
�u�Ή��̂Ȃ��ꍇ�̂�����v���s�����߂ɂ́C���炩���߂����Q�Q�̃f�[�^�̕��U���������ƌ��Ȃ��邩�ǂ������ׂȂ���Ȃ�Ȃ��D
��Excel�́u���̓c�[���v�𗘗p���邽�߂ɂ�
Excel2010, Excel2007�̂Ƃ�Excel2010�̏ꍇ
�t�@�C�����I�v�V�������A�h�C�����i���[�̊Ǘ�����Excel�A�h�C���ƂȂ��Ă���Ƃ��ɂ��̉E�́m�ݒ�n���N���b�N�j�����̓c�[���Ƀ`�F�b�N��t���遨�n�j
Excel2007�̏ꍇ
���j���[�̂����m�z�[���n�̍��ɂ���ۂ�Office�{�^�����N���b�N�����[�ɂ���Excel�̃I�v�V�������A�h�C�����i���[�̊Ǘ�����Excel�A�h�C���ƂȂ��Ă���Ƃ��ɂ��̉E�́m�ݒ�n���N���b�N�j�����̓c�[���Ƀ`�F�b�N��t���遨�n�j
Excel2002�̏ꍇ
�c�[�����A�h�C�������̓c�[���Ƀ`�F�b�N��t���遨�n�j
�@�f�[�^���f�[�^���� Excel2002�̂Ƃ� �@�c�[�������̓c�[�� ���e����F�Q�W�{���g�������U�̌��聨
�E�ϐ�1�̓��͔͈�(1)�Ƃ��� B1:B11�Ə�������
�i�܂��͓��͗��̉E�ɂ���  ���N���b�N���CB1����B11�܂Ńh���b�O����D�j ���N���b�N���CB1����B11�܂Ńh���b�O����D�j
�E�ϐ�2�̓��͔͈�(2)�Ƃ��� C1:C11�Ə�������
�i�܂��͓��͗��̉E�ɂ��� ���N���b�N���CC1����C11�܂Ńh���b�O����D�j
�E��L�̂悤�ɕϐ�1�C2�̓��͔͈͂�����1�C����2�Ƃ������x�����܂�ł���ꍇ�́C�����Łm���x���n�Ƀ`�F�b�N��t����D
�i���͔͈͂�B2:B11�����C2:C11�Ƃ����Ƃ��͂��́m���x���n�ɂ̓`�F�b�N��t���Ȃ��D���̏ꍇ�́C���ɂ��闓�����̓��[���̏o�͌��ʂɂ����āu�ϐ�1�v�Ƃ��āC�E�ɂ��闓���u�ϐ�2�v�Ƃ��ĕ\������邪�C���̓c�[���𗘗p����Ƃ��̓��x�����܂߂�悤�ɂ���������₷��������₷���D�������C���x�����̂𐔒l��1�Ƃ�2�Ƃ��ɂ���ƁC�f�[�^�͈͂ƍ����������ɃG���[�����o����Ȃ��̂ŁC���x���ɂ͕K����������g�p����悤�ɂ���D�j
�E�����͗L�Ӑ����ŁC�f�t�H���g��0.05���������܂�Ă���i�L�Ӑ���5���Ō��肷�邱�Ƃ�\���Ă���D�L�Ӑ���1���̌�����s���ꍇ�͂��̐�����0.01�ɂ���D�j
�E���x��������s���Ƃ��ɁC�o�̓I�v�V������V�K���[�N�V�[�g��V�K�u�b�N�ɂ��Ă���ƃ��[�N�V�[�g��Excel�t�@�C�����ǂ�ǂ��Ă�₱�����Ȃ�̂ŁC�f�[�^�̉E���Ȃǂ̌��₷���͈͂ɏo�͂���悤�ɂ��邽�߂ɂ́C�u�o�̓I�v�V�����v�Łu�o�͐�v��I�ԂƉE�̋��������߂�悤�ɂȂ�̂ŁC�����ɏo�͂������͈͂̍���[�̃Z���Ԓn���������ށD���̏ꍇ�C���łɂ���f�[�^���㏑������邨���ꂪ����Ƃ��͌x�����o��D
��OK���̕\�̂悤�ȏo�͌��ʂ�������D
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
�y�o�͌��ʂ̓ǂݕ��z
�ˁ@�ϑ����ꂽ���U�䂪1.69�łe���E�l�Б���3.18�ł��邩��C�e�l�����E�l�������������U�ɂ͗L�Ӎ����F�߂�ꂸ�C�����U�Ƃ݂Ȃ���D �i�܂��́C�o�Б���0.22��5���i0.05�j�����傫������C���U�ɂ͗L�Ӎ����F�߂�ꂸ�C�����U�Ƃ݂Ȃ���D�j �}�S 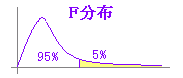 �@�}�R�̗�ł�26.681/15.75122222=1.693900297��5�����E�l�����������̂ŗL�Ӎ����Ȃ��Ɣ��f����D���̕��U��͍����ɒu�����f�[�^�̕��U���E���ɒu�����f�[�^�̕��U�Ŋ��������̂ƂȂ��Ă���̂ŁC���ȏ��ʂ�ɂe������s�����߂ɂ́C���U�̑傫�����̃f�[�^�������ɒu���Ȃ���Ȃ�Ȃ��D �@ |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
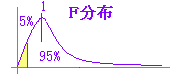
�@�������C�ǂ���̕��U���傫�����͂���Ă݂Ȃ��ƕ�����Ȃ��̂ŁC���炩���ߕ��U���v�Z���邱�ƂȂ��e������s�����Ƃ��C�����̕��U���E���̕��U�����������Ȃ��Ă��܂����ꍇ�ɂ́C���̐}�̂悤�ɕ��U�䂪0�ɋ߂��قǁi�������قǁj���U�ɗL�Ӎ������邱�ƂɂȂ�D�i���U�䂪�P�ɋ߂���Q�̕��U�͓������ƌ��Ȃ��邪�C���q���������Ȃ�قǕ��U���0�ɋ߂Â��D�j
 �}�T
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(2) ��������s��
�@��L�̗�ł͓����U�ƂȂ����̂ŁC�u�������������ꍇ�̂�����v���s���DExcel2010, Excel2007�̂Ƃ� �@�f�[�^���f�[�^���� Excel2002�̂Ƃ� �@�c�[�������̓c�[��
��t
����F�����U�����肵���Q�W�{�ɂ�錟�聨
�E�ϐ�1�̓��͔͈�(1)�Ƃ��� B1:B11�Ə�������
�i�܂��͓��͗��̉E�ɂ��� ���N���b�N���CB1����B11�܂Ńh���b�O����D�j
�E�ϐ�2�̓��͔͈�(2)�Ƃ��� C1:C11�Ə�������
�i�܂��͓��͗��̉E�ɂ��� ���N���b�N���CC1����C11�܂Ńh���b�O����D�j
�E��L�̂悤�ɕϐ�1�C2�̓��͔͈͂�����1�C����2�Ƃ������x�����܂�ł���ꍇ�́C�����Łm���x���n�Ƀ`�F�b�N��t����D
�i���͔͈͂�B2:B11�����C2:C11�Ƃ����Ƃ��͂��́m���x���n�ɂ̓`�F�b�N��t���Ȃ��D
�E�u��W�c���ς��������v�Ƃ����A�������ɑΉ����邽�߂ɂ́C�������ςƂ̍��ق̗���0�ɂ���D�i���ς̍���0�Ƃ������������肷��j
�i���̗��͋̂܂܂ł��f�t�H���g��0������j
�E�����͗L�Ӑ����ŁC�f�t�H���g��0.05���������܂�Ă���i�L�Ӑ���5���Ō��肷�邱�Ƃ�\���Ă���D�L�Ӑ���1���̌�����s���ꍇ�͂��̐�����0.01�ɂ���D�j
�E���x��������s���Ƃ��ɁC�o�̓I�v�V������V�K���[�N�V�[�g��V�K�u�b�N�ɂ��Ă���ƃ��[�N�V�[�g��Excel�t�@�C�����ǂ�ǂ��Ă�₱�����Ȃ�̂ŁC�f�[�^�̉E���Ȃǂ̌��₷���͈͂ɏo�͂���悤�ɂ��邽�߂ɂ́C�u�o�̓I�v�V�����v�Łu�o�͐�v��I�ԂƉE�̋��������߂�悤�ɂȂ�̂ŁC�����ɏo�͂������͈͂̍���[�̃Z���Ԓn���������ށD���̏ꍇ�C���łɂ���f�[�^���㏑������邨���ꂪ����Ƃ��͌x�����o��D
��OK���̕\�̂悤�ȏo�͌��ʂ�������D
�y�o�͌��ʂ̓ǂݕ��z
�ˁ@���l��-3.4�ŗ�������̋��E�l��2.1�ł��邩��C|��|>2.1�ƂȂ��ĕ��ςɗL�Ӎ�������D �@���̕��̓c�[���ł͍����i����1�j�̕��ς��E���i�����Q�j�̕��ς����������Ƃ��ɂ��l�����i�t�Ȃ�ΐ��j�ŕ\������C�m�����E�l�����n������Βl���傫����ΊO���ɗ���D �i�܂��́C�o������0.003��5���i0.05�j��������������L�Ӎ�������D�j
�@
���V���������Q������āC�]���̎����P�������ʌ��ʂ����邩�ǂ����ɊS������悤�ȏꍇ�͎����Q�̕��ς��傫���Ƃ����A�������������ĕБ�������s�����ƂɂȂ�D�i�Б����肩�������肩�̓f�[�^�̒l�Ō��܂�̂łȂ��C���͎҂����ɊS������̂��ɂ��D�j
�� |��| �̒l�͊O���ɍs���قǑ傫���Ȃ�D �}�V 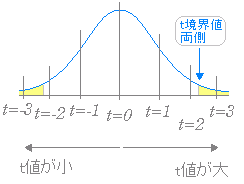 �i�A�j�@|���l|>�����E�l ���� �i�C�j�@p�l<0.05 �̂����ꂩ�ŗL�Ӎ�������Ɣ��f�ł���D �}�W 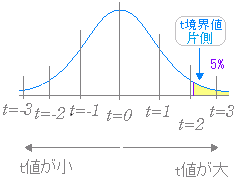
�A������ H0�F��1=��2
�Η����� H1�F��1<��2 �@���̏ꍇ�́C�o�͌��ʂ̂����Б��̕������邱�ƂɂȂ�D�Б�����̋��E�l�͗�������̂Ƃ����������ɗ���̂ŗL�Ӎ��͔F�߂��₷���Ȃ�D�i��L�̏o�͌��ʂ̂����Ct ���E�l �Б� 1.734063592�Ct ���E�l ���� 2.100922037 ������ƕБ��̕����������D�j �@ |
||||||||||||||||||||||||||||||||||||||||||
�@�E�̕\�͂���w���̐��k25�l�i�j�q15�l�C���q10�l�j�̐��w�̓��_�ł���Ƃ���D�j�q�Ə��q�Ƃŕ��ϒl�ɗL�Ӎ������邩�ǂ������肵�Ă�������. �߂Ă��������D�Ȃ��C�����͑�3�ʂ��l�̌ܓ����ď�����2�ʂ܂ŋ��߂Ă��������D
�e����ɂ��Ă͕��̓c�[����p����Ǝ��̂悤�ɏo�͂����̂ŁC1.83, 3.03, 0.18 �̏��ɓ�����D�i���l�̏����ɒ��Ӂj
������ɂ��Ă͕��̓c�[����p����Ǝ��̂悤�ɏo�͂����̂ŁC2.33, 2.07, 0.03 �̏��ɓ�����D�i���l�̏����ɒ��Ӂj
�@
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
�@�E�̕\�͂Q�̃N���X�`�C�a�̐��k�ɂ��Ă���l�𑪒肵�����ʂ��Ƃ��܂��D�����Q�̃N���X�̕��ςɗL�Ӎ������邩�ǂ������肵�Ă�������. �߂Ă��������D�Ȃ��C�����͑�3�ʂ��l�̌ܓ����ď�����2�ʂ܂ŋ��߂Ă��������D
�e����ɂ��Ă͕��̓c�[����p����Ǝ��̂悤�ɏo�͂����̂ŁC3.16, 3.02, 0.04 �̏��ɓ�����D�i���l�̏����ɒ��Ӂj
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
������ɂ��Ă͕��̓c�[����p����Ǝ��̂悤�ɏo�͂����̂ŁC2.64, 2.14, 0.02 �̏��ɓ�����D�i���l�̏����ɒ��Ӂj
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
�@�E�̕\�͂��鋳�Ȃ��������Ŏw�������w���ƐV�����Ŏw�������w���̃e�X�g���ʂ��Ƃ��܂��D�V�����̎w�����@�ɂ͌��ʂ�����ƌ����邩�ǂ������肵�Ă�������. �߂Ă��������D�Ȃ��C�����͑�3�ʂ��l�̌ܓ����ď�����2�ʂ܂ŋ��߂Ă��������D
�@�^����ꂽ�\�̂܂�Excel�̕��̓c�[���ɂ��e������s���ƁC�V�����i�E�̗��j�̕��U�̕����傫�����߁C���̂悤�ɕ��U��C�e���E�l���P���������Ȓl�ŕ\�������D���̂܂ܔ��f����Ƃ��͊ϑ����ꂽ���U��0.79���e���E�l�Б������傫�����番�U�ɂ͗L�Ӎ����Ȃ��Ɣ��f����D�i�o�l�͖��߂��邪�e�l�͊e�X�̋t���œ����邱�ƂɂȂ�F�e�l��1/0.79=1.27�C�e�Б����E�l��1/0.4026=2.48�C���l�͂��̂܂�0.33�ł悢�D�j
�j
�@��ӂɂ����ĕ��U�䂪1�����傫���Ȃ�悤�ɂƂ�ɂ́C�����ƉE�������ւ��Ăe������s���C���̕\�����Ƃɔ��f����悢�D
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| �@
�@�e����ɂ�蓙���U�ƌ��Ȃ��邩��C�����U�̏ꍇ�̂�������s���D���̍ہC�����ɋ������̓��_��u���Ƃ��͍����̕��ς��Ⴂ�̂ł��l�����̒l�ɂȂ邪���̐�Βl�Ƃ����E�l�Ƃ��r����D
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 �@�������C�قƂ�ǂ�F����ŁC���U�ɗL�Ӎ�������ƌ��Ȃ��Ƃ��́C��v����ꍇ�͊܂߂Ȃ��̂ŁCF����͕Б�����ōs���D
�@�������C�قƂ�ǂ�F����ŁC���U�ɗL�Ӎ�������ƌ��Ȃ��Ƃ��́C��v����ꍇ�͊܂߂Ȃ��̂ŁCF����͕Б�����ōs���D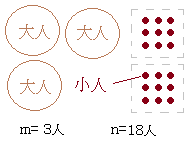 �@�o�X��̂悤�ɑ�l�����Ə��l�����őS�R�Ⴄ���z���W�߂�Ƃ��́C��l�̐l���𐔂��āC�q�l�͂܂Ƃ߂đ�l�̉��l���ɂȂ邩�Ɗ��Z���Ă��瑫���悢�ƍl����D
�@�o�X��̂悤�ɑ�l�����Ə��l�����őS�R�Ⴄ���z���W�߂�Ƃ��́C��l�̐l���𐔂��āC�q�l�͂܂Ƃ߂đ�l�̉��l���ɂȂ邩�Ɗ��Z���Ă��瑫���悢�ƍl����D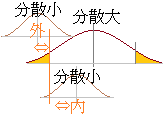 �@�s�����U��p��0.05�ȉ����ۂ��́C���U�̑傫���������Ŕ��f���āC����±1.96�Ђ͈͓̔��ɑ�����̕��ς����邩�ǂ��������ꍇ�Ƃقڈ�v����D
�@�s�����U��p��0.05�ȉ����ۂ��́C���U�̑傫���������Ŕ��f���āC����±1.96�Ђ͈͓̔��ɑ�����̕��ς����邩�ǂ��������ꍇ�Ƃقڈ�v����D