→ スマホ用は別頁
|
=== 読者が配色を変更したい場合 ===
◎外側の色を変えるには,次の色をクリック
《体験・入門レベル》
== Rによるヒストグラム,散布図の作成 == R version 4.0.3, 4.0.4Patched ----- 最終更新年月日:2021.3.30
○この教材は,体験・入門のレベルで,30分から1時間ほどで「そこそこ分かる」ことを目指します.
1. ヒストグラム
1.1 棒グラフとヒストグラムの違い
度数分布表と棒グラフ20人の生徒の朝食が,次のようになっていたとする.パン,ご飯,シリアル,なし,シリアル,なし,ご飯,シリアル,
data1<-c(パン,ご飯,シリアル,・・・,パン,ご飯)
これを関数table( )を使って集計すると「度数分布表」になる.
table(data1)
ご飯 シリアル トースト なし
5 6 4 5
barplot(table(data1))
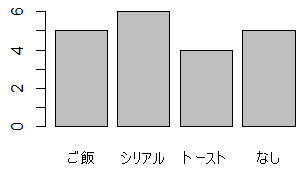 この棒グラフでは,カテゴリ(区分,分類)はデータとして与えられており,与えられたカテゴリごとの「度数」が「棒の高さ」として表示される.
この棒グラフでは,カテゴリ(区分,分類)はデータとして与えられており,与えられたカテゴリごとの「度数」が「棒の高さ」として表示される.※グラフィック・ウィンドウを表示したとき Rでグラフィック・ウィンドウを表示したとき,元のRコンソールが見えなくなることがある.
(1) Rコンソールが見えなくなったら,R上端にあるメニュー画面で「ウィンドウ→1 R Console」を選ぶとよい.
(2) Rのウィンドウ選択画面は,たぶん縦と横の関係が独特の解釈になっていて,通常のWindows画面で使われている縦横の関係が逆になっているように思う. すなわち,「ウィンドウを縦に並べて表示する」とは,通常は「日」の字の形に並ぶと予想するが,Rでは「日」の字の形に並ぶ.同様にして,「ウィンドウを横に並べて表示する」とは,その逆になる. |
階級幅とヒストグラムこれに対して,次のような数値データ(20人の生徒の数学の得点とする)
87,21,27,36,87,48,78,51,40,11,
このデータをベクトルdata1に取り込んで,
45,22,82,68,40,89,23,48,61,73
data1<-c(87,21,27,36,・・・,73)
Rの関数hist( )を使うと
hist(data1)
次のようなグラフが描ける.

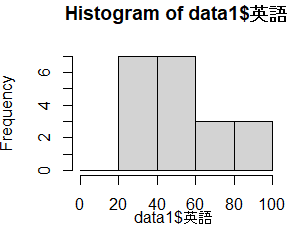
また,棒グラフとは異なり,棒の境界線にはすき間を空けない. 次のようなデータフレーム(文字列,数値を含む表)から,数値データの列を指定して,ヒストグラムにすることもできる. data2 番号,男女,芸術,数学,英語 1,女,音楽,52,66 2,男,美術,28,23 3,男,美術,32,30 4,男,書道,94,67 5,女,書道,50,48 6,男,美術,60,90 7,男,書道,34,77 8,女,書道,23,59 9,女,音楽,88,55 10,女,美術,24,54 11,女,音楽,31,21 12,男,美術,89,24 13,女,音楽,62,56 14,女,美術,33,88 15,女,美術,87,31 16,女,書道,40,54 17,女,音楽,89,91 18,男,美術,75,52 19,男,美術,83,32 20,女,書道,46,24
hist(data2$数学)
• $を付けると列を表すことができる.
• 列ラベルには日本語の漢字・カナ・かなも使うことができる. |